大数据采集与抽取 方法、流程与实践解析
大数据时代,数据已成为驱动决策、优化流程与创新的核心资产。海量、异构、高速的数据特性使得如何高效、准确地采集与抽取数据成为一项关键技术挑战。本文将系统性地解析大数据采集与抽取的核心方法、流程与实践要点,助您构建坚实的数据基础。
一、大数据采集:多源数据的汇聚
大数据采集旨在从各类数据源中获取原始数据,其核心在于覆盖全面、实时高效与确保质量。
1. 主要数据源类型
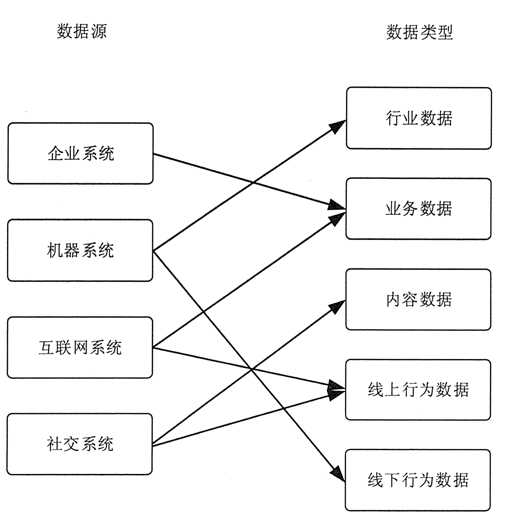
业务数据库:如MySQL、Oracle等关系型数据库中的交易、用户信息。
日志文件:服务器、应用程序、网络设备等产生的日志,是用户行为与系统状态的重要记录。
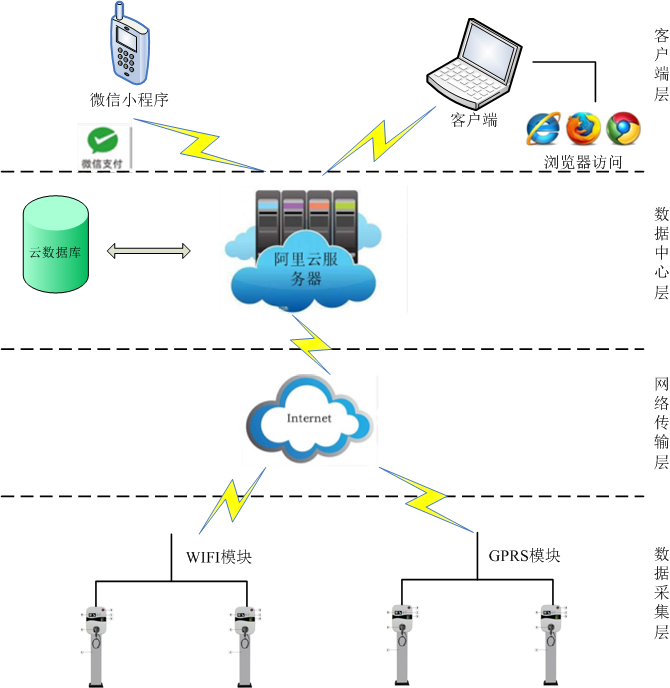
传感器与物联网数据:来自工业设备、智能终端等的实时时序数据。
社交媒体与公开网络数据:通过API接口或网络爬虫获取的文本、图像、视频等非结构化数据。
* 企业内部文档与报表:如PDF、Word、Excel等格式的文档数据。
2. 关键采集方法
批量采集:适用于对实时性要求不高的历史数据同步,如每日定时全量或增量导出数据库快照。常用工具有Sqoop(用于Hadoop与关系数据库间转移)、DataX等。
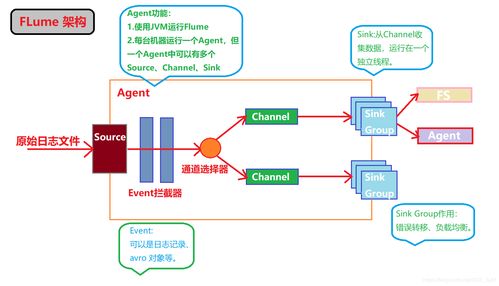
实时/流式采集:用于处理连续不断的数据流,要求低延迟。典型技术包括Apache Kafka(作为高吞吐分布式消息队列)、Flume(日志采集聚合系统)以及基于CDC(变更数据捕获)的数据库监听技术。
API接口调用:从开放平台或内部系统通过规范接口获取结构化数据,是获取第三方数据的主要方式。
网络爬虫:针对网页内容的自动化抓取,需处理页面解析、反爬策略与伦理法律边界。
3. 实践要点
明确需求与范围:根据分析目标确定采集的数据类型、粒度、频率与历史回溯深度。
保证数据质量:在采集端初步校验数据的完整性、格式一致性,避免“垃圾进,垃圾出”。
* 考虑可扩展性与成本:设计能够随数据量增长而线性扩展的架构,并平衡计算、存储与带宽成本。
二、大数据抽取:从原始数据到可用信息
数据抽取通常指从采集到的原始数据(特别是非结构化或半结构化数据)中,提取出有分析价值的、结构化的信息。它是数据清洗、转换与加载(ETL)流程的关键前端环节。
1. 核心抽取场景与技术
文本信息抽取:
结构化字段抽取:如从日志中提取时间戳、错误代码、用户ID。常用正则表达式或分词工具。
- 实体识别(NER):识别文本中的人名、地名、组织名、产品名等。
- 关键词与主题提取:利用TF-IDF、TextRank等算法或LDA主题模型获取文本核心内容。
- 情感与观点抽取:分析文本的情感倾向(正面/负面)或具体观点。
- Web数据抽取:
- 使用XPath、CSS选择器或正则表达式从HTML中定位并提取特定元素内容。
- 借助可视化爬虫工具或深度学习模型处理复杂JavaScript渲染页面。
- 图像与视频数据抽取:
- 应用计算机视觉技术进行OCR文字识别、物体检测、场景分类等,将视觉信息转化为结构化标签或文本描述。
- 音频数据抽取:
- 通过语音识别(ASR)技术将语音转换为文本,再进行文本分析。
2. 抽取流程的一般步骤
1. 数据解析:根据原始数据的格式(JSON、XML、CSV、HTML等)进行解析,转化为程序可处理的内存对象。
2. 模式识别与定位:确定目标信息的模式或所在位置。对于结构化数据,可能是字段映射;对于文本或网页,需编写规则或训练模型来定位。
3. 信息提取与结构化:执行提取操作,并将结果组织成结构化的格式(如数据库表、JSON对象)。
4. 质量验证与纠错:检查抽取结果的准确性和完整性,可通过规则校验、抽样人工复核或利用历史数据进行比对。
3. 技术选型与工具
传统规则引擎:适用于格式稳定、规律明显的数据,开发快但维护成本可能随规则增多而上升。
机器学习/深度学习:适用于复杂、多变的非结构化数据(如自然语言、图像)。需要标注数据训练模型,初期投入大但泛化能力好。预训练模型(如BERT用于NLP,CNN用于CV)大幅降低了应用门槛。
混合方法:结合规则与机器学习,用规则处理简单明确的部分,用模型处理复杂模糊的部分,平衡效率与效果。
常用工具/库:Apache Nifi(数据流自动化)、BeautifulSoup、Scrapy(网页抓取与抽取)、NLTK、Spacy(自然语言处理)、Tesseract(OCR)、Apache Tika(文档内容提取)等。
三、整合架构与最佳实践
一个完整的大数据采集与抽取系统,往往需要将多种方法和技术串联起来,形成自动化数据管道。
1. 典型架构模式
Lambda架构:同时包含批处理层(处理历史全量数据)和速度层(处理实时流数据),在服务层合并结果,兼顾全面性与时效性。
Kappa架构:简化版,将所有数据视为流,统一用流处理框架(如Apache Flink、Spark Streaming)处理,简化系统复杂度。
2. 核心最佳实践
元数据管理:详细记录数据源的schema、采集频率、抽取规则、数据血缘等信息,确保可追溯、可理解。
容错与监控:设计重试机制、死信队列,并监控数据流量、延迟、错误率等关键指标,保障管道稳定运行。
* 迭代与优化:随着数据源变化和业务需求演进,定期评估和优化采集与抽取规则、模型,持续提升数据质量与处理效率。
###
大数据采集与抽取是构建数据价值链的起点,其成功实施依赖于对业务需求的深刻理解、对数据特性的准确把握以及对合适技术与工具的灵活运用。它并非一劳永逸的项目,而是一个需要持续迭代和优化的过程。通过建立稳健、灵活、可扩展的数据摄入管道,企业方能为其后的数据存储、分析与应用打下坚实基础,真正释放大数据的巨大潜能。
如若转载,请注明出处:http://www.antscloudsec.com/product/62.html
更新时间:2026-06-19 10:26:10