大数据系统架构分析 实时用户数据采集与分析系统的实践探索
在数据驱动的时代,实时用户数据采集与分析已成为企业洞察市场、优化产品与提升用户体验的关键。达内大数据培训机构的课程深入剖析了这一领域的核心技术,本文将结合其实践教学,探讨实时大数据系统架构的设计与实现,重点聚焦于大数据采集环节。
一、 系统架构概览
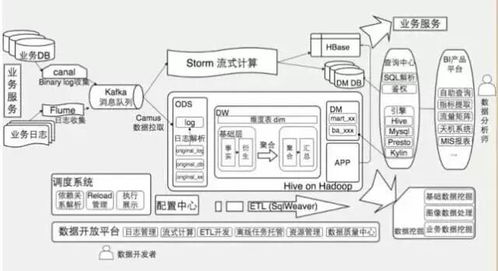
一个典型的实时用户数据采集与分析系统通常采用分层架构,以确保高可用性、可扩展性与低延迟。其核心层次包括:
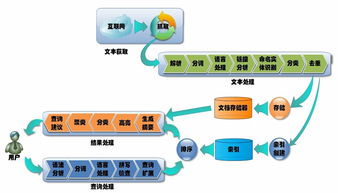
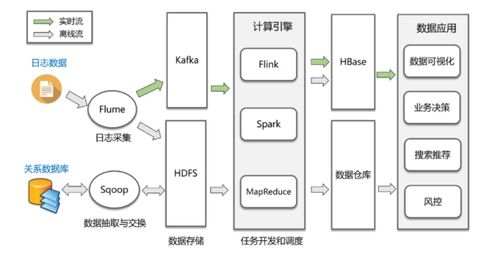
- 数据采集层: 作为系统的“感官”,负责从各类终端(如Web、App、IoT设备)实时收集用户行为数据。常用技术包括埋点SDK、日志收集代理(如Flume、Logstash)以及消息队列(如Kafka)的前端生产者。
- 数据缓冲与传输层: 使用高吞吐量的消息中间件(如Apache Kafka)作为数据总线,对采集的海量数据进行缓冲、解耦生产与消费速率,并确保数据有序、不丢失地传输至下游。
- 实时计算层: 利用流处理框架(如Apache Flink、Apache Storm、Spark Streaming)对数据进行实时清洗、过滤、聚合与复杂事件处理,生成低延迟的指标与洞察。
- 数据存储与服务层: 处理后的结果可存入多种存储系统,如实时OLAP数据库(如ClickHouse、Druid)、时序数据库或键值存储,并通过API服务向业务系统(如实时大屏、推荐系统、风控系统)提供数据查询。
二、 大数据采集:实践的核心起点
数据采集是后续所有分析的基石,其质量与效率直接决定系统价值。达内大数据的课程强调以下实践要点:
1. 采集策略与埋点设计
- 全埋点与代码埋点结合: 全埋点(无埋点)可自动采集通用用户行为,快速上线;代码埋点则针对关键业务事件进行精准、自定义的数据收集,两者结合确保数据全面性与灵活性。
- 数据模型标准化: 设计统一的事件模型(如“谁-在何时-何地-做了什么-结果如何”),规范事件(Event)和属性(Properties)的定义,为后续分析奠定基础。
2. 采集端技术实现
- Web端: 通常使用JavaScript SDK,通过图片请求(GET)、Ajax或Beacon API发送数据。需处理好浏览器兼容性、页面卸载时的数据可靠提交(如使用
sendBeacon)以及跨域问题。
- 移动端(App): 集成轻量级SDK,在考虑用户流量与电量的前提下,采用适当的网络策略(如Wi-Fi下上传)、数据压缩、本地缓存与分批上报机制,保障用户体验与数据完整性。
- 数据格式与协议: 采用JSON等轻量级格式,通过HTTP/HTTPS或直接写入消息队列的协议进行传输,确保数据可读性与传输安全。
3. 高可靠与高性能保障
- 客户端缓存与重试: 在网络异常时,数据先在本地持久化缓存,待网络恢复后按序重传,防止数据丢失。
- 服务端接收与缓冲: 采集服务器(或直接接入Kafka)需具备高并发处理能力,通过负载均衡集群分散压力,并迅速将数据抛入消息队列,避免后端处理瓶颈影响前端采集。
- 数据验证与清洗: 在采集入口或传输过程中进行初步的数据格式校验与过滤,剔除明显无效或恶意数据,减轻下游计算负担。
三、 达内实践教学的启示
达内大数据的相关课程不仅讲解理论架构,更注重通过项目实战让学员掌握:
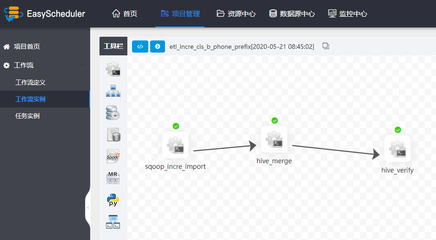
- 工具链运用: 亲手搭建从Flume/Kafka进行日志采集,到Flink实时处理,最终可视化呈现的完整Pipeline。
- 问题排查能力: 学习如何监控数据采集量、延迟、丢失率等关键指标,并诊断从客户端到服务端的数据链路问题。
- 架构权衡思维: 理解在数据准确性、实时性、系统成本与开发效率之间做出平衡的决策方法。
###
实时用户数据采集与分析系统的构建是一个系统工程。一个健壮、高效的采集层是这一切的源头活水。通过对架构的深入理解与持续的技术实践,企业能够将海量、高速的用户数据流,转化为驱动业务增长的实时智能。达内大数据培训的体系化教学,正是为培养能驾驭这一复杂系统的专业人才而设计。
如若转载,请注明出处:http://www.antscloudsec.com/product/41.html
更新时间:2026-06-19 07:36:45